
Designing a Wardrobe Database
Problem solving is the business of every professional, and one personal problem that's always irked me are the inherent issues with managing one's wardrobe. I aim to solve it with data!
If you're anything like me, you can't help but try to represent life as problems to solve and successes to celebrate through data. If you're like me, a prominent problem to solve is our wardrobe.
I often find myself wearing the same "x" shirts and "y" pants, no matter how my wardrobe choices grow. Tastes change, preferences morph, and we struggle to reflect such throughout and end up keeping clothes that could much better serve someone else.

I asked myself, "What if I could battle sentimentality with concrete data about use frequency of a given item?" "What if I could capture changing preferences and tastes?" "What if I could evaluate clothing items objectively and ensure future article purchases are sound ones?"
As you might expect, it sounds like an excellent data project.
The Project
Defining the problem as above and beginning with such an end in mind, it became clear to me I was faced with a project encompassing 1) a custom data source, 2) regular data entry, 3) exploratory data analysis, 4) modeling various components, and 5) custom visualizations.
First up is a custom data source, with several requirements:
- Track clothing items and their varying features (i.e. color, size, pattern, brand, etc.)
- Track tags and statuses for items of clothing (i.e. ripped, too small, athletic, etc.)
- Track item owners (trying to think ahead for a more scalable solution)
- Track the use of wardrobe articles, or "outfits"
I wanted more experience designing and managing a database, in addition to deploying such to the cloud at some point, practicing SQL statements, and using R and/or Python for analysis, modeling, and visualization.
I set out to diagram the data structure with LucidChart. It became apparent that most clothes will have multiple materials, multiple colors, and even multiple patterns; translation, many-to-many relationships.
I solved these with association tables which would also track the share of color, material, or pattern is associated with a particular item (i.e. shirt is 70% red, 30% blue). Tracking outfits follows a similar approach.
It took quite a bit of time to consider the situation from all angles and design an appropriate structure.
The Design
I decided to use MySQL, local to my machine for the time being, to host the structure. This presented several benefits initially though also possessed some complications as I'll detail in the future.
I finished the Entity Relationship Diagram (ERD) below with as much detail as possible. I specified the appropriate primary, foreign, and alternate keys; table and field names; the cardinality of relationships; and the relevant data types.
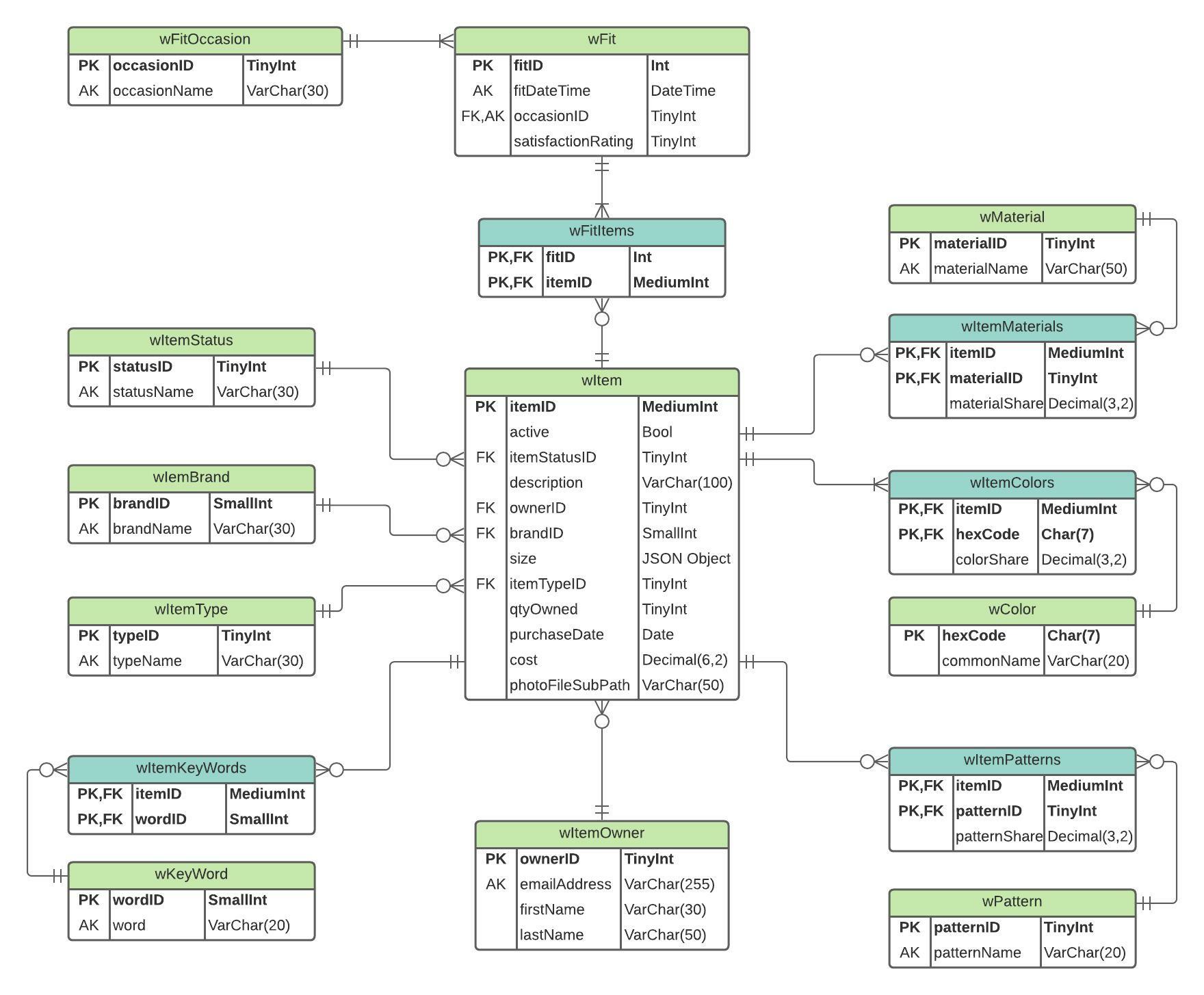
The structure and detail may seem a bit overkill, however, I want this to be a sustainable solution for myself and potentially others. Also, I think such a dataset could be really unique and I'm strongly considering sharing portions of it publicly in events such as #TidyTuesday or Kaggle.
I also really want to practice many of steps along the data pipeline. From tracking data to managing a data source, to data transfer and wrangling. From visualization and machine learning, to even creating an app for this data.
The possibilities are endless for this project and design was just the start. Click the blue link at the top of this post to learn more about this project and read additional project component posts.